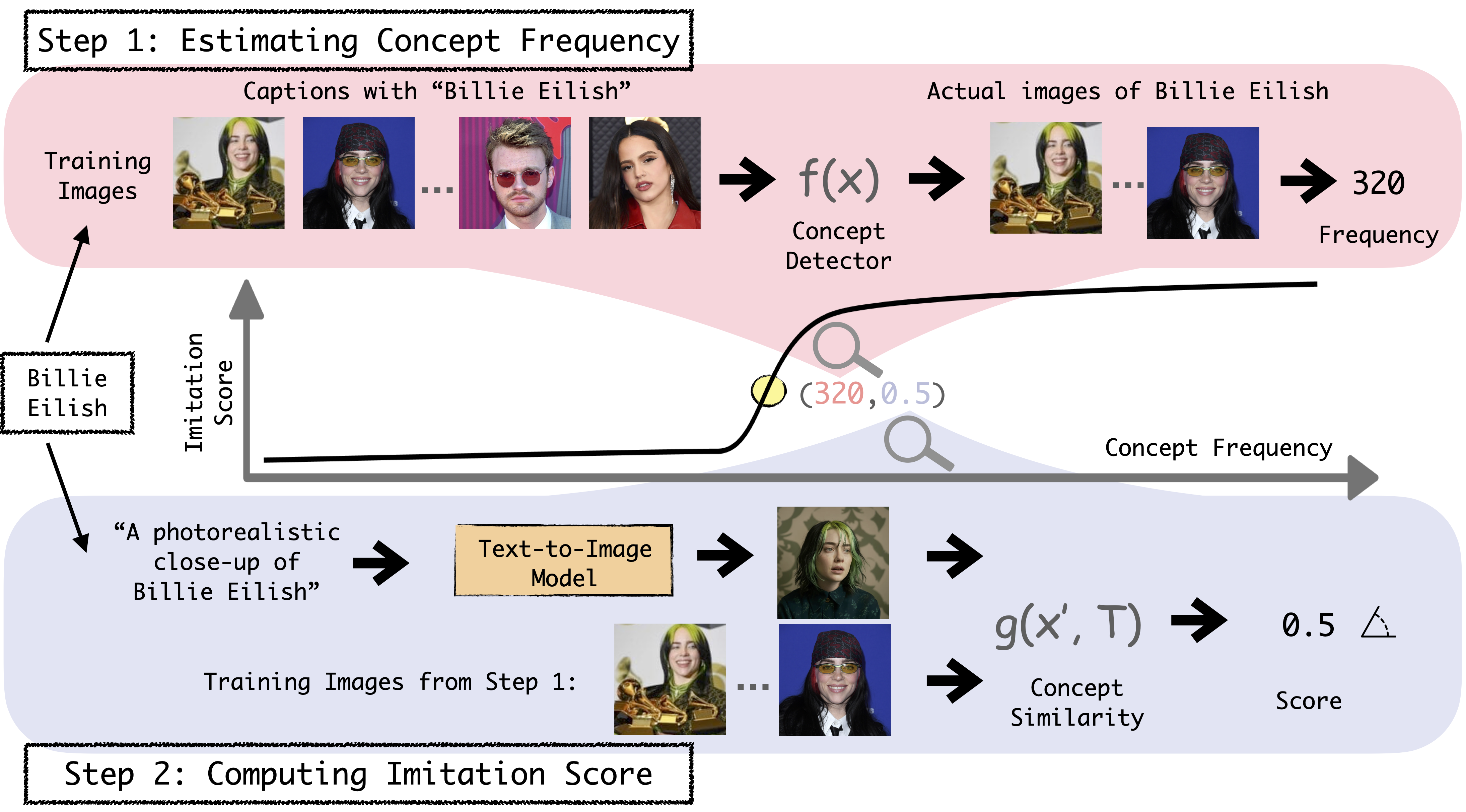
Model: Stable Diffusion 1.1
Prompt: "A photorealistic close-up photograph of {celebrity}"
Image Count: We count the number of images of a celebrity by using a celebrity specific detector applied to the images whose caption mention that celebrity.
MIMETIC2 Overview
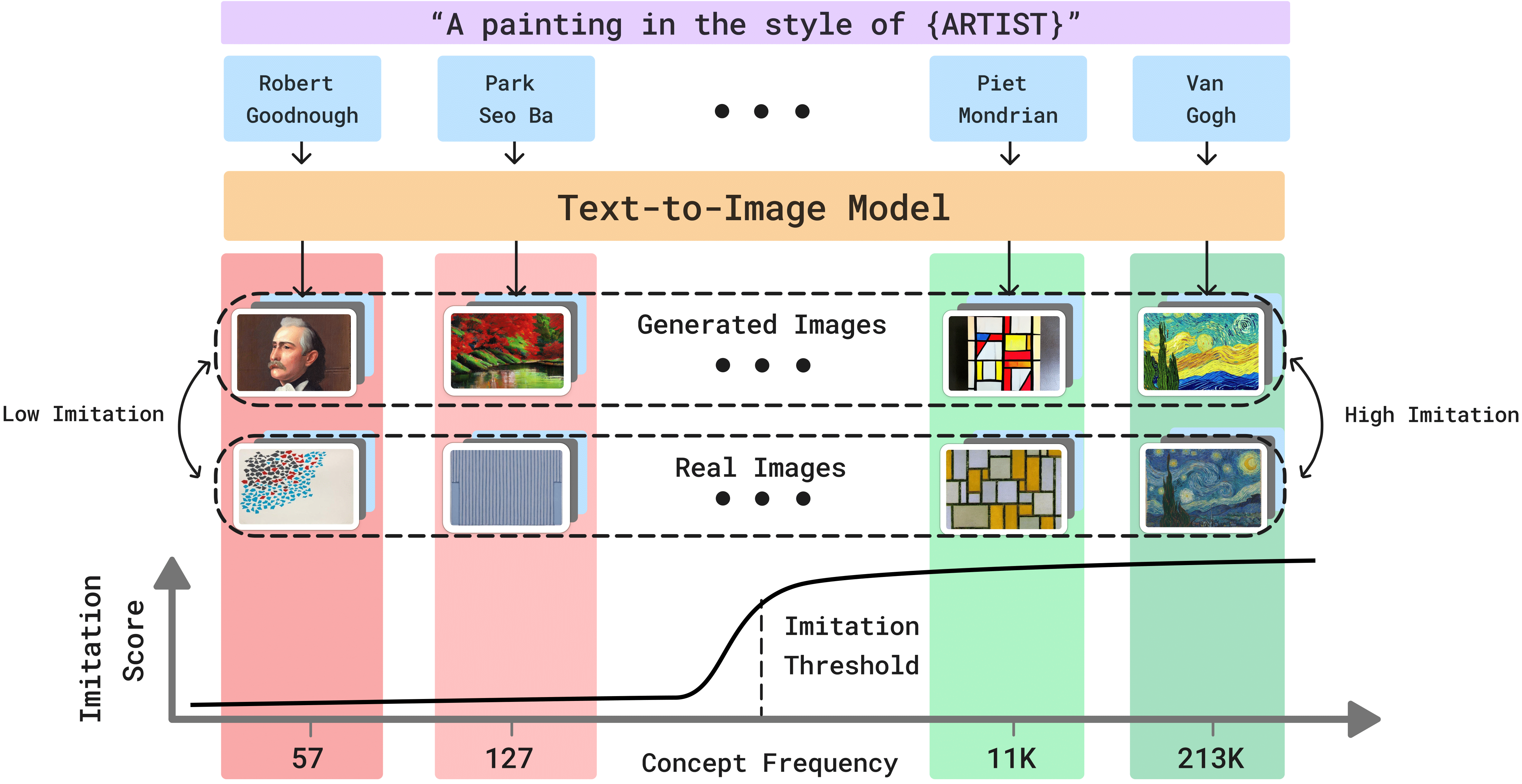
An overview of FIT, where we seek the imitation threshold -- the point at which a model was exposed to enough instances of a concept that it can reliably imitate it. The figure shows four concepts (e.g., Van Gogh's art style) that have different frequencies in the training data (213K for Van Gogh). As the frequency of a concept's images increases, the ability of the text-to-image model to imitate it increases (e.g. Piet Mondrian and Van Gogh). We propose an efficient approach, MIMETIC2, that estimates the imitation threshold without training models from scratch.